В полном соответствии с философией “быстрого прекращения” доступ к словарю dict с помощью конструкции d[k] возбуждает исключение, если ключ k отсутствует.
Любой питонист знает об альтернативной конструкции d.get(k, default), которая применяется вместо d[k], если иметь значение по умолчанию удобнее, чем обрабатывать исключение KeyError.
Однако если нужно обновить найденное значение (при условии, что оно изменяемое), то и __getitem__, и get оказываются неудобны и неэффективны.
В примере №1 показан неоптимальный скрипт, демонстрирующий одну ситуацию, когда dict.get – не лучший способ обработки отсутствия ключа.
Пример №1 основан на примере Алекса Мартелли, он генерирует индекс, показанный в примере №2. Оригинальный скрипт представлен на слайде 41 презентации Мартелли “Учим Python заново”. Его скрипт демонстрирует использование dict.setdefault, показанное в примере №3.
Пример №1. example0.py: применение метода dict.get для выборки и обновления списка вхождений слова в индекс(в примере №3 показано лучшее решение).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
""" Строит индекс, отображающий слово на список его вхождений """ import sys import re WORD_RE = re.compile('\w+') index = {} with open(sys.argv[1], encoding='utf-8') as fp: for line_no, line in enumerate(fp, 1): for match in WORD_RE.finditer(line): word = match.group() column_no = match.start() + 1 location = (line_no, column_no) # некрасиво, написано только для демонстрации идеи occurrences = index.get(word, []) # (1) occurrences.append(location) # (2) index[word] = occurrences # (3) # напечатать в алфавитном порядке for word in sorted(index, key=str.upper): # (4) print(word, index[word]) |
1. Получить список вхождений слова word или [], если оно не найдено.
2. Добавить новое вхождение в occurrences.
3. Поместить модифицированный список occurrences в словарь dict, при этом производится второй поиск в индексе.
4. При задании аргумента key функции sorted мы не вызываем str.upper, а только передаем ссылку на этот метод, чтобы sorted могла нормализовать слова перед сортировкой. Если кратко, мы используем метод в качестве полноправной функции.
Пример №2. Частичная распечатка результата работы скрипта №1, примененного к “Дзен Python”. В каждой строке присутствует слово и список его вхождений в виде пар(номер-строки, номер колонки).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
pythonlearn.ru@admin:~$ python3 example0.py zen.txt a [(19, 48), (20, 53)] Although [(11, 1), (16, 1), (18, 1)] ambiguity [(14, 16)] and [(15, 23)] are [(21, 12)] aren [(10, 15)] at [(16, 38)] bad [(19, 50)] be [(15, 14), (16, 27), (20, 50)] beats [(11, 23)] Beautiful [(3, 1)] better [(3, 14), (4, 13), (5, 11), (6, 12), (7, 9), (8, 11), (17, 8), (18, 25)] break [(10, 40)] by [(1, 20)] cases [(10, 9)] Complex [(6, 1)] complex [(5, 23)] complicated [(6, 24)] counts [(9, 13)] dense [(8, 23)] do [(15, 64), (21, 48)] Dutch [(16, 61)] easy [(20, 26)] enough [(10, 30)] Errors [(12, 1)] explain [(19, 34), (20, 34)] ... |
Три строчки, относящиеся к обработке occurrences в примере №1, можно заменить одной, воспользовавшись методом dict.setdefault. Пример №1 ближе к оригинальному примеру Алекса Мартелли.
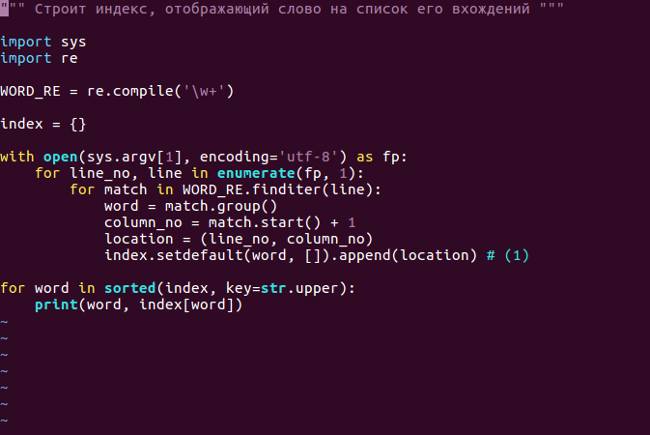
Пример №3. example.py: применение метода dict.setdefault для выборки и обновления списка вхождений слова в индекс. В отличие от примера №1, понадобилась только одна строчка.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
""" Строит индекс, отображающий слово на список его вхождений """ import sys import re WORD_RE = re.compile('\w+') index = {} with open(sys.argv[1], encoding='utf-8') as fp: for line_no, line in enumerate(fp, 1): for match in WORD_RE.finditer(line): word = match.group() column_no = match.start() + 1 location = (line_no, column_no) index.setdefault(word, []).append(location) # (1) # напечатать в алфавитном порядке for word in sorted(index, key=str.upper): print(word, index[word]) |
1. Получаем список вхождений слова word или устанавливаем его равным [], если оно не найдено. Теперь список можно обновить без повторного поиска.
Как накрутить 1000 офферов на страницу, сколько это будет стоить? Портал pricesmm.com сравнивает прайсы сервисов, анализирует цены на биржах и сайтах-обменниках и делает выводы. А также рассуждает, чем офферы Вконтакте отличаются от живых подписчиков, и можно ли заметить это отличие.
Иными словами, строка:
|
1 |
my_dict.setdefault(key, []).append(new_value) |
дает такой же результат, как:
|
1 2 3 |
if key not in my_dict: my_dict[key] = [] my_dict[key].append(new_value) |
с тем отличием, что во втором фрагменте производится по меньшей мере два поиска ключа(три, если ключ не найден), тогда как setdefault довольствуется единственным поиском.